如自定义 KafkaSerializationSchema。且调用 FlinkKafkaProducer(String defaultTopic,KafkaSerializationSchema serializationSchema,Properties producerConfig,FlinkKafkaProducer.Semantic semantic) 构造器。...
”flink kafka“ 的搜索结果
flink作为实时流处理平台,可以与kafka很好地结合。 因为flink流处理的特点,需要source和sink作为流处理的源头和终端。与kafka的结合,可以让flink作为生产者,不断的向kafka消息队列中产生消息。...
flinkKafka.rar



1.背景介绍 在现代大数据处理领域,流处理技术已经成为了核心技术之一。流处理是一种实时数据处理技术,它可以在数据流中进行实时分析和处理,从而实现对数据的实时挖掘和应用。在流处理技术中,Apache Flink和...
1.背景介绍 Zookeeper是一个开源的分布式协调服务,用于构建分布式应用程序的基础设施。它提供了一种可靠的、高性能的、分布式协同的方法,以实现分布式应用程序的一致性。Apache Flink是一个流处理框架,用于处理...

Flink 整合 Kafka 基本步骤,请参考:Flink 基础整合 Kafka。本文仅用来介绍 Flink 整合 Kafka 实现 Exactly-Once。 1.什么是Exactly-Once 恰好处理一次的意思。不管在处理的时候是否有异常发生,计算的结果都...
前言 在消息处理过程中,除了Flink程序本身的逻辑(operator),我们还需要和外部系统进行交互,例如本地磁盘文件,HDFS,Kafka,Mysql等。虽然Flink本身支持Exactly-Once语义,但是对于完整的数据处理系统来说,...
Flink中的广播流(BroadcastStream)是一种特殊的流处理方式,它允许将一个流(通常是一个较小的流)广播到所有的并行任务中,从而实现在不同任务间共享数据的目的。广播流在处理配置信息、小数据集或者全局变量等...

全国职业技能大赛(高职组)大数据试卷分析 介绍 了使用Flink处理Kafka中的数据


互联网大厂比较喜欢的人才特点:对技术有热情,强硬的技术基础实力;主动,善于团队协作,善于总结思考。无论是哪家公司,都很重视高并发高可用技术,重视基础,所以千万别小看任何知识。面试是一个双向选择的过程,...
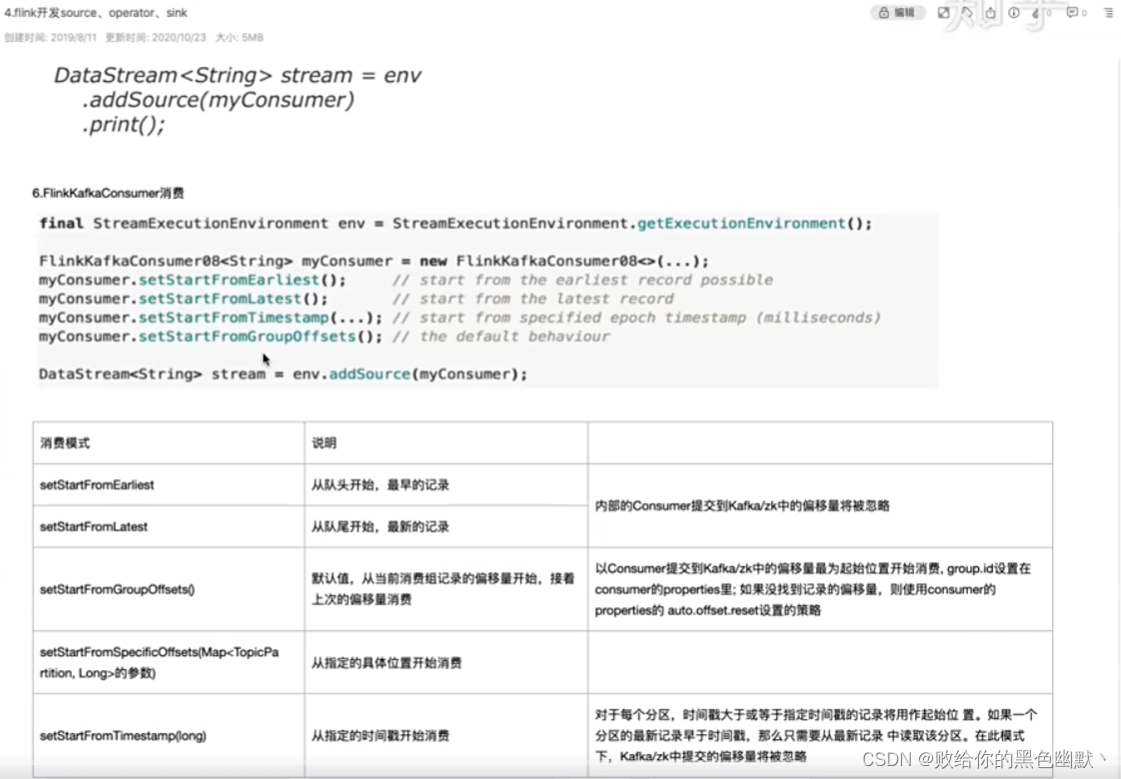

flink高级版本后,消费kafka数据一种是Datastream 一种之tableApi。上官网。


import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.connectors.kafka.{...
flink大数据流式处理框架,提高开发效率
网址:https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/datastream/kafka/1、flink的kafkaSource默认是把消费的offsets提交到当前Task的状态中,并不会主动提交到kafka的——...

Flink数据发送到kafka,并自定义Kafka分区; 注意这里是通过FlinkkafkaProducer将数据发送到kafka;跟下面的检查点是不一样的 FlinkkafkaProducer下的消费保障总共分为3级别 val kafkaSink = new FlinkKafkaProducer...
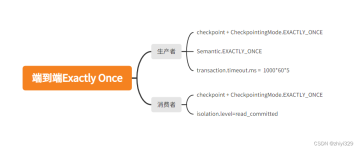
flink消费kafka消息
先总结三种方式,这三种就是常见的.
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地